Software Reliability
Software Reliability and Service
RELIASS offers a range of services targeted at improving the reliability, dependability and safety of your software. Whether your software is safety-critical, mission-critical, or expected to satisfy strict reliability and availability requirements to be certified as market-ready, we can lead and support your effort in attaining these goals.
Software Failures
Before we list the tasks undertaken to analyze software reliability and safety it is important to understand the meaning of a failure due to software. Software does not exhibit the random or wearout related failure behavior we see in hardware. Software will always function in the same way as long as the same input and computer states are present. Software can cause system failures either because of design errors or implementation errors. Design errors are often caused by wrong assumptions about system operation, e. g., that input A is always followed by input B. Typical implementation errors are caused by confusing symbols, such as g instead of G. Software faults will only cause failures if the fault is encountered during usage. Therefore faults existing in often used code will cause failures more often than faults residing in rarely used code but the latter can be equally serious. In mission or safety critical applications it is particularly important to review and test rarely used code.
Software Reliability
As is the case for hardware, software reliability engineering involves much more than analysing test results, estimating remaining faults, and modeling future failure probabilities.
Although in most organizations software test is no longer an afterthought, management is almost always surprised by the cost and schedule requirements of the test program, and it is often downgraded in favor of design activities. Often adding a new feature will seem more beneficial than performing a complete test on existing features.
A good software reliability engineering program, introduced early in the development cycle, will mitigate these problems by:
- Preparing program management in advance for the testing effort and allowing them to plan both schedule and budget to cover the required testing.
- Continuous review of requirements throughout the life cycle, particularly for handling of exception conditions. If requirements are incomplete there will be no testing of the exception conditions.
- Offering management a quantitative assessment of the dependence of reliability metrics (software/system availability; software/system outages per day etc) on the effort (time and cost) allotted to testing.
- Providing the most efficient test plan targeted to bringing the product to market in the shortest time subject to the reliability requirements imposed by the customer or market expectations.
- Continuous quantitative assessment of software/system reliability and the effort/cost required to improve these by a specified amount. Our software reliability engineers are experienced in all the stages and tasks required in a comprehensive software reliability program.
We can support or lead tasks such as:
- Reliability Allocation
- Defining and Analyzing Operational Profiles
- Test Preparation and Plan
- Software Reliability Models
Reliability Allocation
Reliability allocation is the task of defining the necessary reliability of a software item. The item may be part of an integrated hardware/software system, may be a relatively independent software application, or more and more rarely, a standalone software program. In either of these cases our goal is to bring system reliability within either a strict constraint required by a customer or an internally perceived readiness level, or optimize reliability within schedule and cost constraints.
RELIASS will assist your organization in the following tasks:
- Derive software reliability requirements from overall system reliability requirements
- When possible, depending on lifecycle stage and historical data, estimate schedule and cost dependence on software reliability goals
- Optimize reliability/schedule/cost based on your constraints and your customer’s requirements
- Ideally, reliability allocation is performed early in the lifecycle and may be modified and refined as both software and other system components are developed. At these early stages, RELIASS can assist in the above tasks with limited design and requirements inputs. As the system develops software reliability allocation becomes more accurate. The dependence of reliability allocation on cost and schedule also solidifies when the software goes into testing. Although it is ideal to begin these tasks early on and follow during system evolution, often organizations do not implement a software reliability program until very late in the software development cycle. The delay may be to the time of test preparation and plan, or even later when testing is yielding results that need to be interpreted to verify or ascertain reliability.
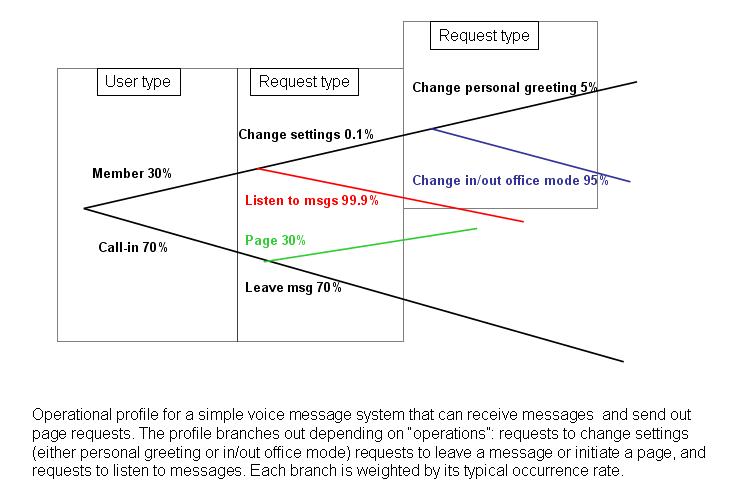
Defining and Analysing Operational Profiles
The reliability of software, much more so than the reliability of hardware, is strongly tied to the operational usage of an application. A software fault may lead to system failure only if that fault is encountered during operational usage. If a fault is not accessed in a specific operational mode, it will not cause failures at all. It will cause failure more often if it is located in code that is part of an often used “operation” (An operation is defined as a major logical task, usually repeated multiple times within an hour of application usage). Therefore in software reliability engineering we focus on the operational profile of the software which weighs the occurrence probabilities of each operation.Unless safety requirements indicate a modification of this approach we will prioritize our testing according to this profile.
We will work with your system and software engineers to complete the following tasks required to generate a useable operational profile:
- Determine the operational modes (high traffic, low traffic, high maintenance, remote use, local use etc.)
- Determine operation initiators (components that initiate the operations in the system)
- Determine and group “Operations” so that the list includes only operations that are significantly different from each other (and therefore may present different faults)
- Determine occurrence rates for the different operations
- Construct the operational profile based on the individual operation probabilities of occurrence.
Test Preparation and Plan
Test preparation is a crucial step in the implementation of an effective software reliability program. A test plan that is based on the operational profile on the one hand, and subject to the reliability allocation constraints on the other, will be effective at bringing the program to its reliability goals in the least amount of time and cost.
Software Reliability Engineering is concerned not only with feature and regression test, but also with load test and performance test. All these should be planned based on the activities outlined above.
The reliability program will inform and often determine the following test preparation activities:
- Assessing the number of new test cases required for the current release
- New test case allocation among the systems (if multi-system)
- New test case allocation for each system among its new operations
- Specifying new test cases
- Adding the new test cases to the test cases from previous releases
Software Reliability Models
Software reliability engineering is often identified with reliability models, in particular reliability growth models. These, when applied correctly, are successful at providing guidance to management decisions such as:
- Test schedule
- Test resource allocation
- Time to market
- Maintenance resource allocation
The application of reliability models to software testing results allows us to infer the rate at which failures are encountered (depending on usage profile) and more importantly the changes in this rate (reliability growth). The ability to make these inferences relies critically on the quality of test results. It is essential that testing be performed in such a way that failure incidence is accurately reported.
Our software reliability engineers will work with developers, testers and program management to apply an appropriate model to your failure data. In order for the model prediction to be useful we must ensure that the assumptions and structure of the model coincide with the underlying coding and testing process. It is not sufficient to find a mathematical function that best fits the data. In order to infer future failure behaviour it is crucial that the underlying assumptions of the model be understood in terms of program management and progress towards release. This requires experience working with the software reliability models as well as an understanding of latent issues in the development and testing process that may influence the test data.
Software Safety
As systems and products become more and more dependent on software components it is no longer realistic to develop a system safety program that does not include the software elements.
Does software fail?
We tend to believe that well written, well tested, safety critical software never fails. Experience proves otherwise with software making headlines when it actually does fail, sometimes critically. Software does not fail the same way hardware does, and the various failure behaviours we are accustomed to from the world of hardware are often not applicable to software. However, software does fail, and when it does, it can be just as catastrophic as hardware failures.
Safety-critical software
Safety-critical software is a creature very different from both non-critical software and safety-critical hardware. The difference lies in the massive testing program that such software undergoes.
What are “software failure modes”?
Software, especially in critical systems, tends to fail where least expected. We are usually extremely good at setting up test plans for the main line code of the program, and these sections usually do run flawlessly. Software does not “break” but it must be able to deal with “broken” input and conditions, which are often causes for “software failures”. The task of dealing with abnormal/anomalous conditions and inputs is handled by the exception code dispersed throughout the program. Setting up a test plan and exhaustive test cases for the exception code is by definition difficult and somewhat subjective.
Anomalous inputs can be due to:
- Failed hardware
- Timing problems
- Harsh/unexpected environmental conditions
- Multiple changes in conditions and inputs that are beyond what the hardware is able to deal with.
- Unanticipated conditions during software mode changes
- Bad user input
- Often the conditions most difficult to predict are multiple, coinciding, irregular inputs and conditions.
- Safety-critical software is usually tested to the point that no new critical failures are observed. This of course does not mean that the software is fault-free at this point, only that failures are no longer observed in test. Why are the faults leading to these types of failures overseen in test? These are faults that are not tested for any of the following reasons:
- Faults in code that is not often used and therefore not well represented in the operational profiles used for testing
- Faults that are due to multiple anomalous conditions that are difficult to test
- Faults related to interfaces and controls of failed hardware
- Faults due to missing requirements
It is clear why these types of faults may remain outside of a normal, reliability focused, test plan.
How does one protect against such failures once software is released?
Current guides and standards are not nearly as specific and clear as the hardware equivalent. Most notably RTCA/DO-178B, the Radio Technical Commission for Aeronautics Software Considerations in Airborne Systems and Equipment Certification document, whose latest version is from 1992, and is considered the main guideline for safety-critical software development does not deal in particular with types of failures and how to avoid them. The document deals mainly with process control that will hopefully ensure good software. It does not dictate how one can verify that the process worked “well enough” for the requirements of any particular system. The much awaited update to this document, DO-178C, is expected in 2011 and will most certainly offer more prescriptive guidelines to the certification of safety-critical software. These will be based not only on more current design environments such as Object Oriented Design but in general model-based software and more current formal methods for verification.
As safety-critical software is most often part of a larger system that includes hardware the safety assessment process should follow the process applied to hardware.
Software Preliminary/Functional Hazard Analysis
If the top level architecture of the system details software components it is necessary that they be included in this qualitative analysis. The PHA is also needed to formulate a software specification that (a) prevents software from interfering with established hazard handling provisions, and (b) directs software design to reinforce hazard handling where established provisions are lacking. The analysis is necessary for completing the later stages of the safety review. We will work with your requirements and specification documents as well as any early design documents and artefacts available. Model based artefacts such as use-case scenarios are very helpful at this level of analysis.
Software System Hazard Analysis and/or Fault Tree Analysis
The quantitative hazard and Fault Tree Analyses should include any software that interfaces with safety-critical hardware.
At this stage Our software safety engineers will work with your design products to provide a complete analysis:
1. System architecture
2. System requirements document
3. Preliminary/functional hazard analysis
4. Hardware failure information
5. Human error information
A common obstacle to including software in a quantitative analysis is the lack of a failure rate estimates for these components. Software can be constructed so that a specified number of failures can be tolerated. If a system is safety critical it is usually assumed that it will be fielded only after stringent testing which will show no remaining defects in the software code (this does not mean 100% reliability though!). Any remaining sources of failure (associated with the software) can be assumed to be the result of incomplete requirement definition, in particular requirements dealing with rare and anomalous conditions such as hardware failures, rare environmental and usage conditions and unforeseen operator actions. Often combinations of multiple rare events will lead to conditions that the software was not prepared for. An approximate rate for such events can be derived from the size and quality of requirements but cannot be fully verified.
If the software is not part of a safety critical system/function it may be fielded with a known failure rate (based on the software testing program). In this case this failure rate may be used as an estimate for the fault tree analysis.
Software Failure Modes and Effects Analysis
Failure Modes and Effects Analysis is done at system level based on the Fault Tree analysis (or hazard analysis) results. The fault tree identifies end effects that are to be mitigated. The FMEA will identify “initiating events” which can lead to these end effects. A software FMEA will identify which initiating events (such as incorrect or missing inputs, particular modes of operation etc) will result in the software causing a system failure. As an example consider incorrect input during a relatively rare operating mode, or a rare input while system is recovering from a hardware failure. The software FMEA is performed only on software components (or subcomponents) that can lead to hazardous conditions and results.
We perform software FMEAs (and system FMEAs that include software) based on an Object Oriented design. In order to perform this analysis, we will require the following design products:
1. System architecture
2. System requirements document
3. System hazard analysis and/or Fault Tree Analysis (can be generated by RELIASS)
4. Software program in an object oriented design environment: this may be in the form of a UML design, a Matlab Simulink design, or the code in any object oriented language (e.g. C++, .NET etc)
5. Hardware failure information
6. Human/operator error information
The FMEA process in an object oriented environment ensures exhaustive identification of exception condition initiators, and verification that protection against faults in exception handling, are in place and effective!
Although slightly different from a hardware FMEA, when properly executed, the software FMEA is compatible with hardware FMEAs and permits a full system FMEA. Hence it provides the assurance, that other certification processes cannot, that we have identified all possible failure modes and have included provisions to detect and protect against them.
Software FMEA – How?
One of the main reasons the FMEA hasn’t been a consistent part of critical software certification is the difficulty in applying it to a large piece of code. RELIASS has developed a methodology that overcomes this problem by using the object view of the program. Whether developed as a UML or Matlab Simulink model, or coded in an object-oriented language such as C++, .Net or Java, we apply our FMEA methodology at the object level.
Along with requirements and design documents we are able to construct a software FMEA that is surprisingly similar to a hardware FMEA, as software “object methods” are equivalent to hardware “parts”. Moreover, when required, we will develop and generate a system FMEA which will include hardware and software and any interface failure modes.
Our method overcomes another inherent software FMEA problem that most professionals cannot escape: the subjectivity of the process. Most software safety professionals will apply the FMEA at a “functional” level. This application is not only problematic in that it can leave entire sections of the exception code unevaluated, but it also introduces a subjectivity into the process that allows more failure modes to be ignored. Our object-centered method removes this subjectivity as it uses the classes defined in the design.
Automated Software FMEA
FMEAs, applied to software or hardware, are a large task. Hardware FMEAs are automated through an exhaustive system breakdown tree, or Bill Of Material. We have develop automated tools and methods for generating the software FMEA based on object-oriented software models. Our tools are currently able to automatically generate the FMEA structure for models developed in UML (Unified Modeling Language) or within the Matlab Simulink environment.
Benefits of using our automated tools include:
- A significant reduction in work load (by several orders of magnitude)
- Assurance of completeness of the task (no failure modes left behind)
- Libraries for future use that reduce work load even more (software and interface components, failure modes, higher order effects, detection methods, compensation provisions).
What Can You Expect From Our Software FMEA Services and Tools?
RELIASS & their Partners provide both consulting services and tools for the Software FMEA. Our services cover the entire spectrum of organizational needs:
- We can perform the entire task of developing the FMEA for your system and generating the complete FMEA reports.
- We can provide consulting to an in-house effort which may include any combination of: training, system set-up, tools and/or continuous program support.
Either way, we will walk you through the process so that your organization is able to successfully complete the FMEA and fully trust the results.
What will our FMEA and reports include?
- List of critical failure modes and whether they have been accounted for in the design;
- List of provisions (detection methods & compensation provisions) required to make the current system safe.
At the end of every effort, the reports and electronic libraries developed in the process will lead to an easier task in future FMEA efforts. As in the case of hardware, a software FMEA is an incredibly valuable addition to the organizational knowledge base, allowing for safer and less costly programs in the future.
Requirements V&V
V&V of software requirements is at least as crucial as V&V for hardware, if not more so. Most serious failures in safety and mission critical software are due to incomplete or incorrect requirement definition. As software does not fail randomly and hardly ever due to actual coding defects, most failures are the result of the code not being designed to deal with certain (mostly rare) events: conditions and inputs. Moreover, it is in the requirements that mitigations for failures are listed. For serious failures, multiple (redundant) mitigation strategies are required. A safety-informed requirements V&V focuses on these types of omissions.
In order to perform a requirements review that can focus on safety-aspects of the code RELIASS requires the following design products:
1. System architecture
2. Complete system requirements documents
3. System hazard analysis and/or Fault Tree Analysis
For more information about our Software Reliability and Safety program please contact us at info@reliass.com
News and Updates
Recent Articles

Metaverse Platform arzMETA to be launched shortly!
Please register your interest if you are interested in the Opportunities Metaverse can offer your Business. What is Metaverse:…

RAM Commander 8.8 is now released
This document describes new features of RAM Commander Version 8.6. The document covers only the features, which were added to the RAM Commander 8.6

Event Tree Analysis
Global provider connected products for consumers, and enterprises worldwide, supply chain control is everything, provide visibility and traceability needed for.
Request A Quote
We take great pride in everything that we do, complete control over products allows us to ensure our customers receive the best quality service.